Carry Lookahead Adder |
Index, Next |
The Ripple Carry Adder was fun, but it's slow:
| Total delay to add two n bit numbers is 2n + 2 gate delays | |
| So, delay adds as bit size increases |
Solution: we'll sacrifice some of our design simplicity and hierarchy for speed.
First step, completely separate the carry portion of the addition from the sum.
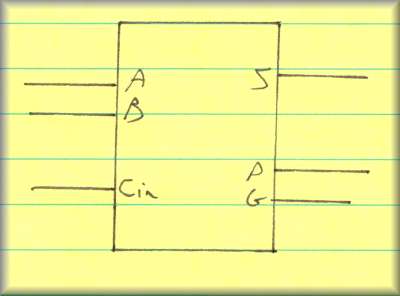
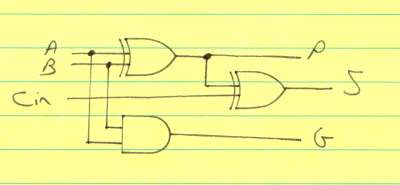
The "sum" part of the CLA is handled by the partial full adder (PFA):
Block diagram
Circuit implementation
The normal "Carry Out" bit found in the Full Adder is replaced with P and G outputs:
Propagate
|
|||||||
Generate
|
Get it? So for the i'th bit of the addition,
| the Carry Ci bit is generated (forced) if Gi is true | |
| the Carry Ci-1 is propagated to Ci if Pi and Ci-1 are both true (note the recursive definition) |
So, let's look at come Carry bits:
|
||
C0 -
This is
the input to the first PFA
|
||
C1 -
Generate
OR propagate the input carry
|
||
C2 -
Generate
OR propagate previous carry... carry logic is expanded, not shared
|
||
C3 -
Generate
OR propagate previous carry... carry logic is expanded, not shared
|
||
C4 - And so
on...
|
Do you see the trick? Carry logic is replicated for each bit (as P/G) rather than reused. Size of the circuit is sacrificed for increased speed.
Reuse 4-bit CLA for 8, 16, 32, 64 bit addtion...
CLA compared to Ripple Carry Adder:
| Faster | |
| Bigger... more components | |
| A more complex design |
Note: A 4-bit CLA is shown on page 130